Overview
We need to model the environmental impact of the computation for the trained model. The training costs of genAI models are often disclosed in some form. These costs must be normalized and then amortized across the expected use-life of the model. The key components of the training cost of the model include:- The operational energy used to train the final model
- The operational energy used to train intermediate and preliminary models
- The embodied emissions from the cluster used to train all models, including hardware reserved but not actively deployed
- (Allocated emissions from generation of the training and test data)
- (Allocated operational and embodied emissions of development and testing infrastructure)
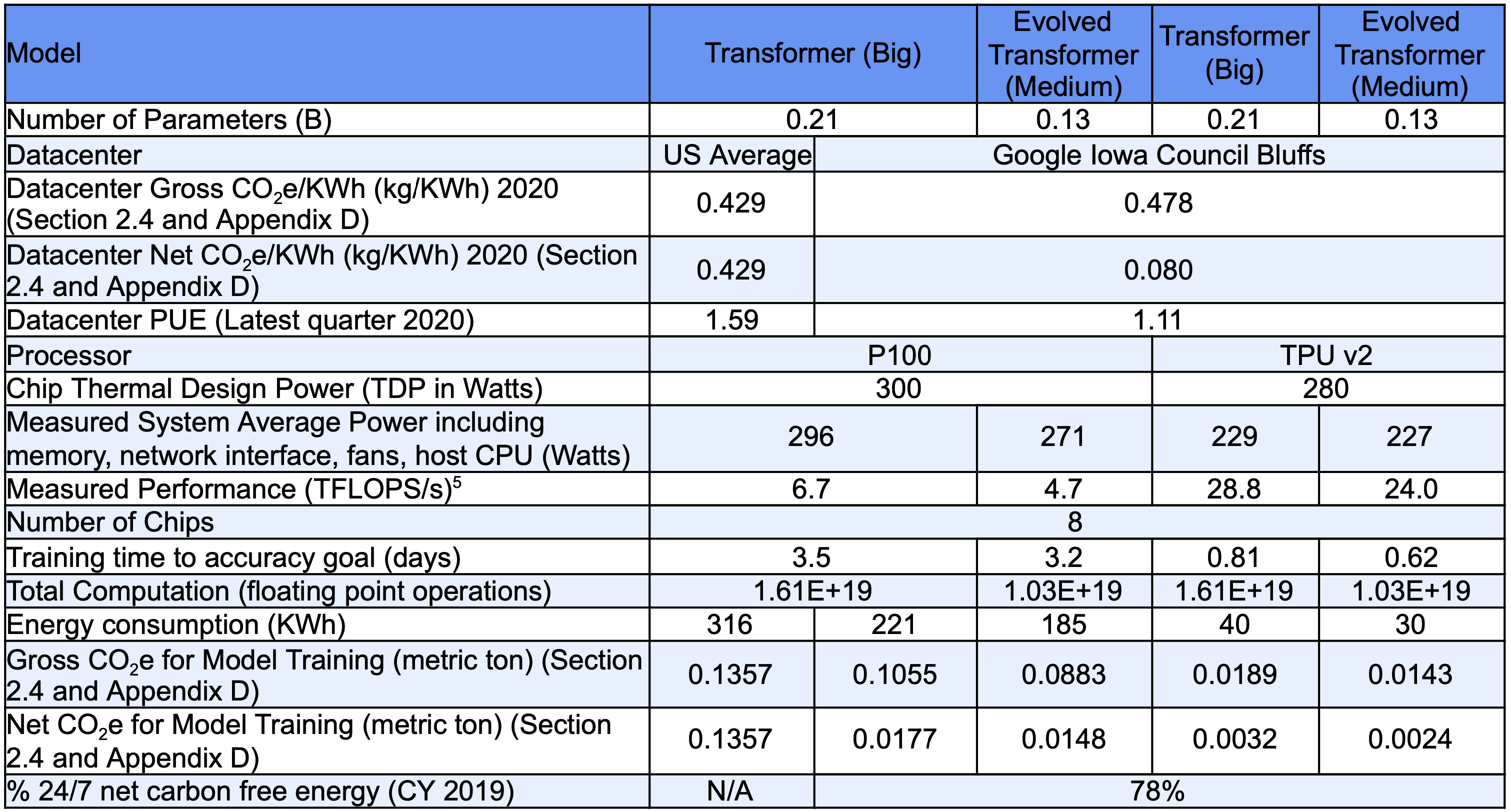
Disclosure of training costs
To fully assess environmental impact, model developers should disclose the technical infrastructure used for training and how this infrastructure was engaged during the training process. Infrastructure data:- Training cluster details
- Training cluster location(s) - if hosted in a cloud, which region(s)
- Total reserved/owned wall clock time for intermediate and final model training
- CPU utilization % for model training
- GPU hours for intermediate model training
- GPU hours for final model training
Example disclosure
As an example of a relatively complete disclosure, see Sasha Luccioni, Sylvain Viguier, and Anne-Laure Ligozat. 2022. Estimating the carbon footprint of Bloom, a 176B parameter language model.: “We estimate that BLOOM’s final training emitted approximately 24.7 tonnes of CO2eq if we consider only the dynamic power consumption, and 50.5 tonnes if we account for all processes ranging from equipment manufacturing to energy-based operational consumption.” Infrastructure data| Component | Disclosed data |
|---|---|
| GPU | Nvidia A100 80GB |
| Server | HPE Apollo 6500 Gen10 Plus |
| Number of GPUs | 384 |
| Number of servers | 48 |
| Training location | France |
| Component | Disclosed data |
|---|---|
| Total reserved time | 118 days |
| Reservation start time | January 2022 (?) |
| GPU hours for final model | 1,082,990 |
Normalization of disclosed data
When disclosed data is not present or not complete, we need to use predictive or heuristic data to fill in the gaps.| Missing data point | Mechanism to replace |
|---|---|
| GPU model | Use the most common GPU for the training year (for instance, 2022 is Nvidia A100) |
| Server model | Use the most common server or instance type for the training year |
| GPUs used | Use the average cluster size for similar models |
| Servers used | Divide GPUs used by average GPUs per server |
| Location | Use the US as a relatively high-carbon country |
| Datacenter PUE | Use location average |
| Datacenter WUE | Use location average |
| Total reserved time | Use the average ratio of reserved time to GPU hours |
| Reservation start time | Use the published model date minus the total reserved time |
| GPU hours for final model | Predict using parameters and architecture per OpenCarbonEval |
| GPU hours for intermediate models | Predict based on ratio of final to intermediate for other disclosed models |
Example normalization: BLOOM 176B
The BLOOM paper includes most of the required parameters for carbon emissions. However, it does not include data for water consumption. We use the fallbacks for the missing data points in the calculations below. Some assumptions:- The 35.8 tons of CO2 for the intermediate models implies proportional reservation and usage as the final model. The total emissions for all models is then 35.8+24.69 tons, so we can extrapolate by a factor of 2.45x.
| Component | Disclosed data |
|---|---|
| Total reserved time | 289 days (118 x 2.45) |
| Reservation start time | August 2021 (finish date of June 2022 minus 289 days) |
| GPU hours for final model | 2,653,326 (1,082,990 x 2.45) |
Calculation of carbon emissions
To calculate CO2 emissions, we use the Software Carbon Intensity formula. We need a few data points:- The usage energy per GPU hour for the cluster
- The embodied emissions per reserved hour for the cluster
- The carbon intensity of the grid in the training location(s) during the training time period
Example carbon calculation
For the final BLOOM model described above:| Component | Value |
|---|---|
| Server embodied emissions | 2500 kgCO2e for similar model |
| GPU embodied emissions | 318 kgCO2e |
| Usage energy per GPU | 428 W |
| Datacenter PUE | 1.1 (Google average) |
| Grid intensity | 57 kgCO2e / kWh |
| Server use life | 4 years given rapid pace of change in GPU market |
| Projected utilization | 95% given intense demand for GPUs |
Calculation of water impact
The water impact of training includes:- The water consumed to cool the servers during the training period (using the “water utilization efficiency” or WUE of the datacenter)
- The water consumed to produce the electricity used by the servers
- The water consumed to produce the chips and servers
Example of water impact calculation for BLOOM 176B
| Component | Value |
|---|---|
| Datacenter WUE | 1.8 L/kWh (US average) |
| Electricity WUE | 3.67 L/kWh - note that 2022 data nuclear data from FR indicates lower numbers that WRI report |
| Manufacturing WUE | 412 L/GPU |
Amortization of impact across use life
A general-purpose model is likely to be used heavily for a period of time then made obsolete by newer models that are more effective and/or more efficient. Specialized models may have longer use lives. Open source models enable fine tuning that will create stickiness for ongoing use. Each model should have a projected use life and track the actual and projected number of inferences for each month during that use life. As actual inference numbers are calculated each month, the projections for the remaining use life should be updated. Since actual inference numbers are sensitive, the model developer could publish the percent of amortized training cost remaining.Amortization schedule tables
Initial amortization schedule PI means the total projected inferences N means the total use life in months TC means the total training cost| Data point | Month 1 | Month 2 | Month 3 | … | Month N |
|---|---|---|---|---|---|
| Remaining use life | N | N - 1 | N - 2 | 0 | |
| Training cost remaining (TCR) | TC | TC - TC / N | TC - 2 x TC / N | 0 | |
| Projected inferences remaining (PCR) | PI | PI x (N - 1) / N | PI X (N - 2) / N | 0 | |
| Training cost per inference (TPI) | TCR1 / PCR1 | TCR2 / PCR2 | TCR3 / PCR3 | 0 | |
| Training cost “billed” (TCB) | TC/N x TPI | TCB1 + TC/N x TPI | TC |
| Data point | Month 1 | Month 2 | Month 3 | … | Month N |
|---|---|---|---|---|---|
| Remaining use life | N | N - 1 | N - 2 | 0 | |
| Training cost remaining (TCR) | TC | TC - TCB1 | TC - TCB2 | 0 | |
| Projected inferences remaining (PCR) | PI | AI1 x (N - 1) / N | AI1 x (N - 2) / N | 0 | |
| Training cost per inference (TPI) | TCR1 / PCR1 | TCR2 / PCR2 | TCR3 / PCR3 | TC / PI | |
| Actual inferences | AI1 | ||||
| Training cost “billed” (TCB) | AI1 x TPI | TCB1 + AI2 x TPI | TC |
Open Questions
- How to estimate projected inferences and use life for a new model (vs an upgrade)
- How to estimate actual inferences for a closed model that doesn’t disclose usage
- How to estimate actual inferences for an open source model like LLAMA where the use is not happening in a centralized fashion
Example of amortization
Traffic to ChatGPT was relatively flat from April 2023 to April 2024, averaging around 50M visits a day. Assuming 5 queries per visit and 925 inferences per query, this would represent 7T inferences per month. With the impending release of GPT-4o, a reasonable projection would be that traffic would continue at the same rate, and that the model lifecycle would be around a year given the 14-month gap between GPT-4 and GPT-4o. The initial amortization schedule would look like:| Data point | Month 1 | Month 2 | Month 3 | … | Month 14 |
|---|---|---|---|---|---|
| Remaining use life | 14 | 13 | 12 | 0 | |
| Training cost remaining (TCR) | 46 mt | 43 mt | 39 mt | 0 | |
| Projected inferences remaining (PCR) | 98T | 91 | 84 | 0 | |
| Training cost per inference (TPI) | .46g/Mq | .46g/Mq | .46g/Mq | 0 | |
| Training cost “billed” (TCB) | 3 mt | 3 mt | 3 mt | 0 |
| Data point | Month 1 | Month 2 | Month 3 | … | Month 14 |
|---|---|---|---|---|---|
| Remaining use life | 14 | 13 | 12 | 0 | |
| Training cost remaining (TCR) | 46 mt | 41 mt | 38 mt | 0 | |
| Projected inferences remaining (PCR) | 98T | 143T | 132T | 0 | |
| Training cost per inference (TPI) | .46g/Mq | .28g/Mq | .28g/Mq | 0 | |
| Actual inferences | 11T | ||||
| Training cost “billed” (TCB) | 5 mt |